AI-Powered Classification & Data Extraction for Scanned Images
Indago processes scanned and faxed documents such as claims forms, invoices and records. Learn why our innovative solution is replacing legacy capture software.
Haystac’s exclusive AI visual recognition methods use both machine and deep learning to classify and separate scanned documents including large PDFs.
This is accomplished without OCR, text analysis, separator sheets, barcodes or other legacy approaches that require a lot of human intervention and hinder your goal for straight-through processing. Haystac’s AI approach requires little to no training or supervision.
Classifies and separates documents using deep-learning-powered visual recognition.
Out-performs legacy template-based systems.
Does not rely on outmoded text and OCR methods.
Works very well on less-than-ideal images.
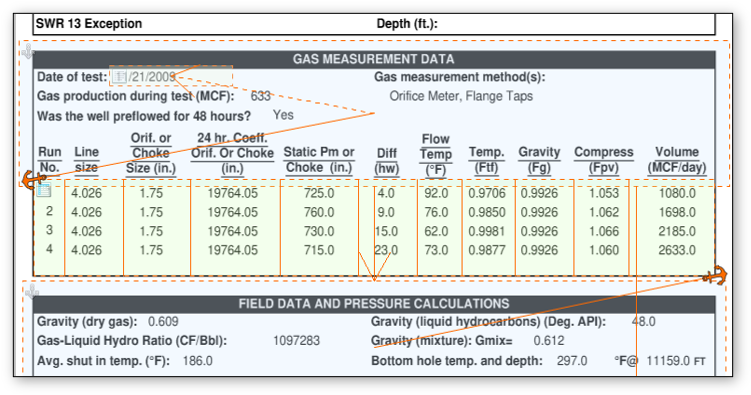
Can handle complex multi-page table structures.
Document Classification
Haystac’s exclusive AI visual recognition methods use both machine and deep learning to classify and separate scanned documents including large PDFs.
This is accomplished without OCR, text analysis, separator sheets, barcodes or other legacy approaches that require a lot of human intervention and hinder your goal for straight-through processing. Haystac’s AI approach requires little to no training or supervision.
Document Classification
Haystac’s exclusive AI visual recognition methods use both machine and deep learning to classify and separate scanned documents including large PDFs.
This is accomplished without OCR, text analysis, separator sheets, barcodes or other legacy approaches that require a lot of human intervention and hinder your goal for straight-through processing. Haystac’s AI approach requires little to no training or supervision.
Data Extraction
Haystac developed a proprietary AI method for data extraction that will outperform legacy capture software.
This is based on Haystac’s exclusive visual anchor technology and is especially effective at improving your extraction accuracy from less-than-ideal scanned images.
Quick Facts
Classifies and separates documents using deep-learning-powered visual recognition.